· Sergio Alexander · javascript · 14 min read
Análisis comparativo de algoritmos de ordenamiento
Análisis comparativo de algoritmos de ordenamiento

Como parte de un ejercicio típico de algoritmia en la universidad, hice un pequeño análisis comparativo de los algoritmos de ordenamiento más populares, buscando estudiar la complejidad de cada uno de estos y como las diferentes formas de resolver un mismo problema pueden afectar los tiempos de ejecución. Quiero aclarar que este es solo un análisis academíco muy simple que quiero documentar, el cual tal vez sirva a futuro para otros estudiantes de ciencias de la computación.
Comence desarrollando un pequeño script en Java que permite generar numeros aleatorios de cinco digitos y almacenarlos en un archivo de texto, esto con el fin de poder analizar el mismo conjunto de datos entre los diferentes algoritmos; el script correspondiente lo pueden hallar en este respositorio y ejecutar de la siguiente forma:
# Ruta del archivo
> algorithms/java/RandomNumbers.java
# Ejecutar script en Java
$ javac RandomNumbers.java && java RandomNumbers
Lo anterior generará el archivo de texto numbers/numbers.txt con n numeros aleatorios que se especifican dentro del script de Java. Dentro de mis experimentos el archivo que generé fue de 1.000.000.000 millones de datos, el cual no adjunto en el repositorio debido a que termino pesando cerca de 5 GB.
En un paso siguiente procedí a implementar los algoritmos de ordenamiento más populares:
- Burbuja (Bubble Sort): Complejidad O(n^2)
- Conteo (Counting Sort): Complejidad O(n+k)
- Montones (Heapsort): Complejidad O(n log n )
- Inserción (Insertion Sort): Complejidad O(n^2)
- Mezclas (Merge Sort): Complejidad O(n log n).
- Rápido (Quicksort): Complejidad O(n log n).
- Selección (Selection Sort): Complejidad O(n^2).
Para esta tarea seleccione el lenguaje C y los scripts obtenidos los pueden encontrar en algorithms/c/sortAlgorithms.
Por último, dado que para hacer un buen análisis se deben correr muchas pruebas, cree un par de scripts que me permitieran automatizarlas de forma tal que se pudieran correr de forma continua sin intervención, estos son:
# Archivo desde el cual se puede correr cualquiera de los algoritmos implementados y permite crear arreglos de forma dinámica con base a la cantidad de elementos a ordenar. Este script además genera dos archivos de salida en el folder "results" con logs sobre los tiempos de ejecución del algoritmo
> algorithms/c/benchmark.c
# Correr prueba
# arg1, arg2 => Son el tipo (nombre) del algoritmo y la cantidad de elementos a probar
$ gcc benchmark.c -o benchmark.out && ./benchmark.out arg1 arg2
# El script runtTest.c permite correr multiples pruebas para los diferentes algoritmos y diferentes cantidades de datos haciendo uso del script anterior
> algorithms/c/runTest.c
# Correr pruebas
$ gcc runTest.c -o runTest.out && ./runTest.out
En este punto ya tenemos todo listo para hacer las pruebas, solo necesitamos poner a correr nuestro archivo runtTest.c en alguna máquina, y dado que esto es un simple ejercicio académico, no requiere de mucho rigor científico, pero procure crear un pequeño ambiente controlado en un par de servidores donde no estuvieran ejecutandose en paralelo otras tareas, dado que los tiempos de ejecución de cada prueba puede verse afectado al estar compartiendo recursos con otros procesos.
Dicho lo anterior cree dos droplets (término para llamar a servidores en la nube) en Digital Ocean, los cuales corresponden a:

Como se puede observar en la imagen anterior, el segundo servidor posee el doble de capacidades de procesamiento, con lo cual se espera obtener un mejor rendimiento en las pruebas.
Finalmente procedo a configurar el servidor asegurandome de tener los compiladores tanto de Java y C; pueden encontrar el archivo de aprovisionamiento que corri en cada uno de los servidores en ServerConfig/provision.sh.
# Base installation
sudo apt-get update -y
sudo apt-get upgrade -y
sudo apt-get install -y build-essential gcc python-dev python-pip python-setuptools
# Git
sudo apt-get install -y git
# Install Java
sudo apt-get install default-jre -y
sudo apt-get install default-jdk -y
sudo apt-get install openjdk-7-jre -y
sudo apt-get install openjdk-7-jdk -y
Resultados
En cada máquina se corrieron las pruebas con el mismo archivo de numeros aleatorios a ordenar, en intervalos inicialmente de 10 en 10, luego 100 en 100, luego 1.000, luego 10.000 etc, hasta 1.000.000.000 de datos; estos resultados se pueden visualizar en el archivo results/analysis.ods.
En este punto hago un parentesis para documentar el truco que utilice para poder correr los el archivo de pruebas en background y de esa forma no depender de una sesion activa en la terminal para correr las mismas:
# Correr pruebas
$ gcc runTest.c -o runTest.out && ./runTest.out
# Detenemos el proceso usando Ctrl + z
# Una vez hecho esto ejecutamos lo siguiente
disown -h %1
bg 1
# Lo anterior básicamente hace que el último proceso que se habia ejecutado corra en background, algo muy similar a lo que hace el &, solo que en este caso si cierro la sesion en la terminal no se detendra el programa.
Al cabo de 3 o 4 días de haber lanzado el archivo runTest.c, revise que los procesos y apenas iban en 1.600.000 de datos, me pareció que era suficiente para sacar conclusiones, así que decidí parar el experimento en ambos servidores; ahora procedo a mostrar los resultados obtenidos comparando los tiempos de respuesta de cada algoritmo en cada máquina haciendo una gráfica de cantidad de datos a ordenar vs tiempo de ejecución.
M1 = Máquina 1 (1 nucleo, 1GB de RAM) M2 = Máquina 2 (2 nucleos, 2GB de RAM)
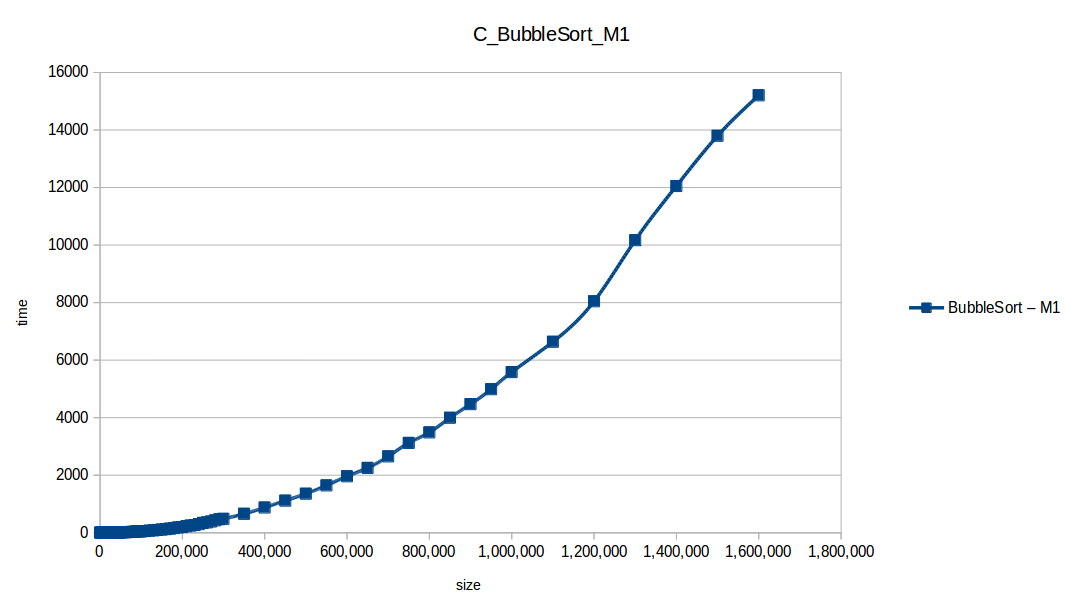
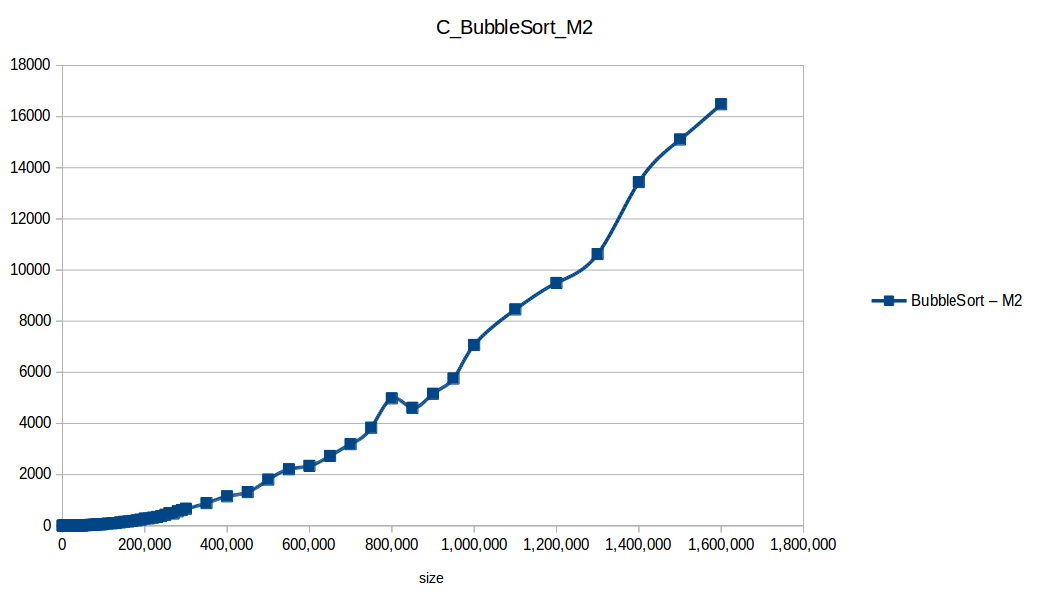
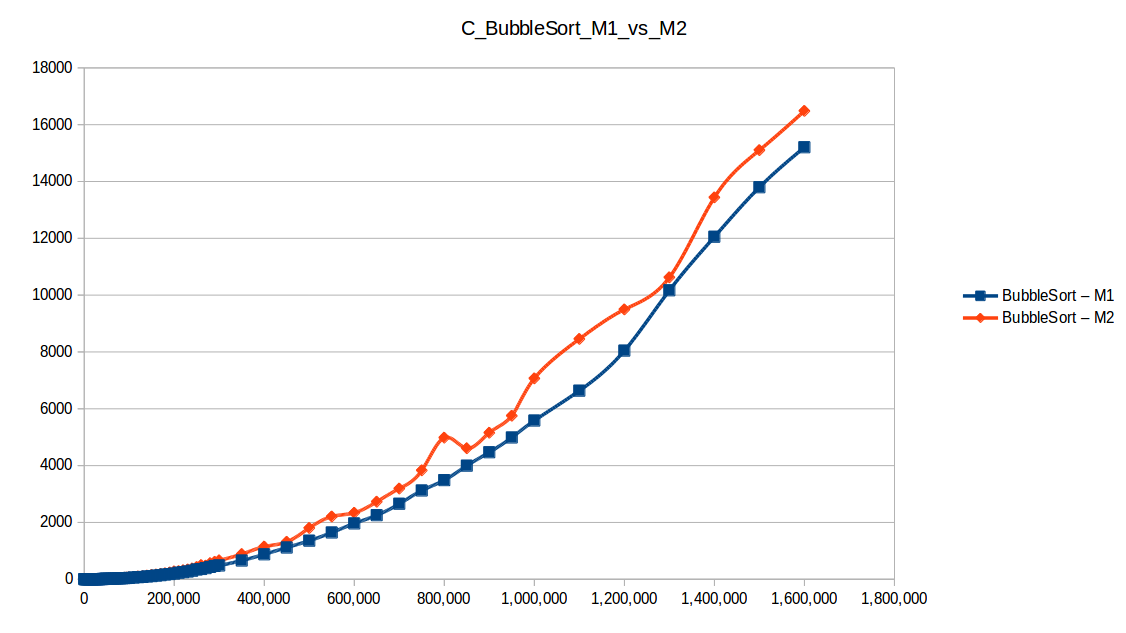
Burbuja (Bubble Sort): O(n^2)
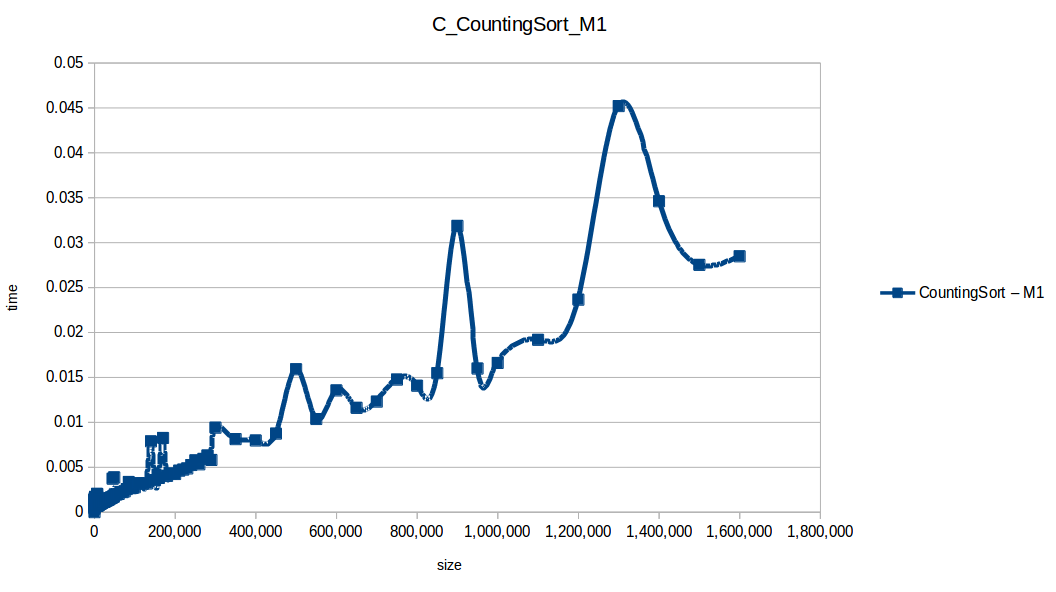
Conteo (Counting Sort): O(n+k)
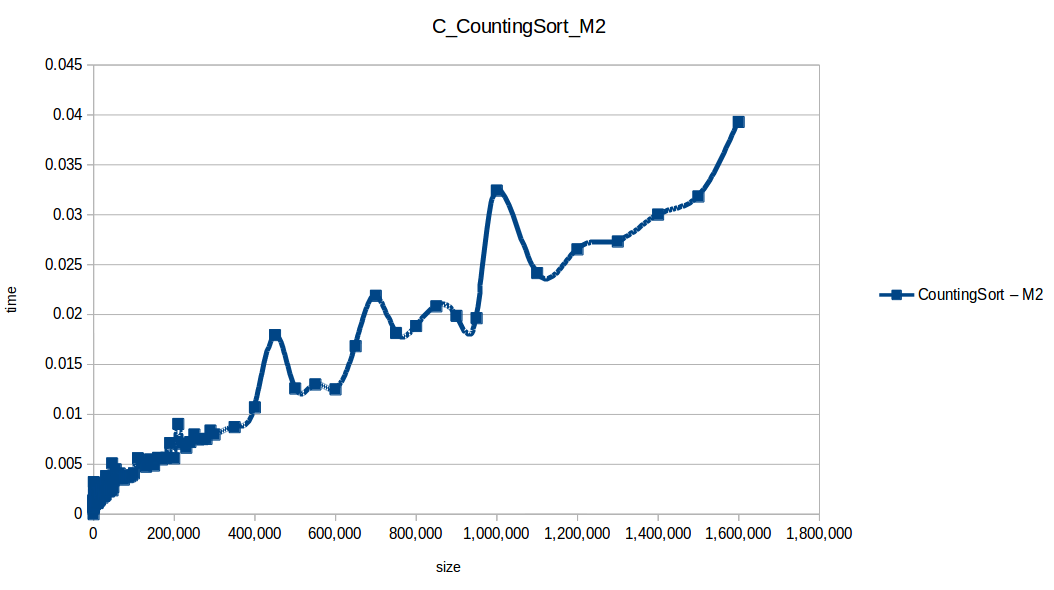
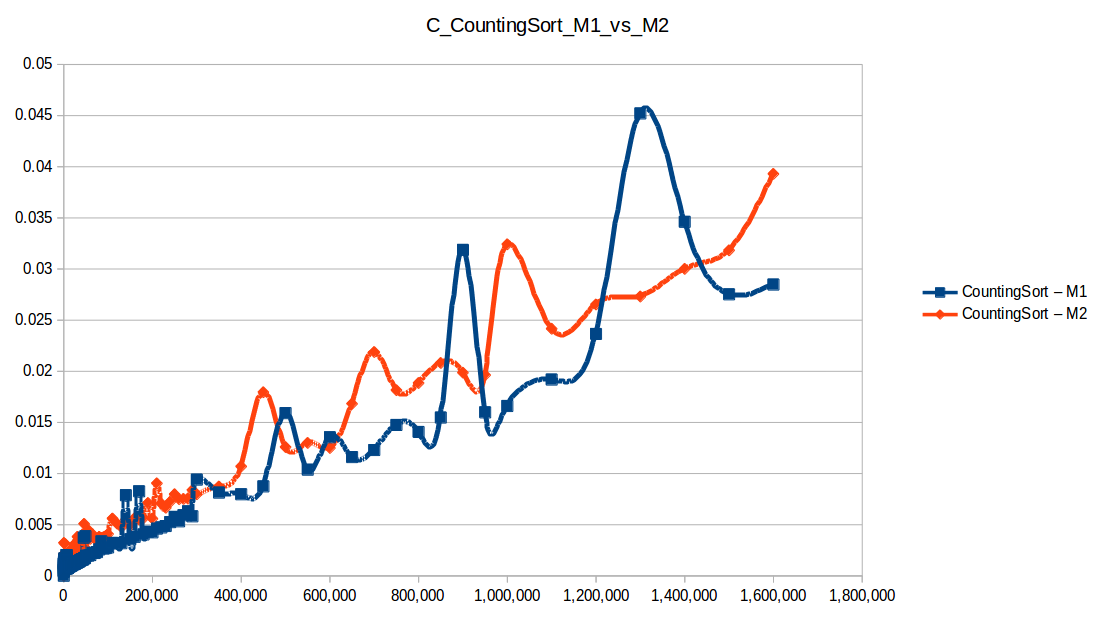
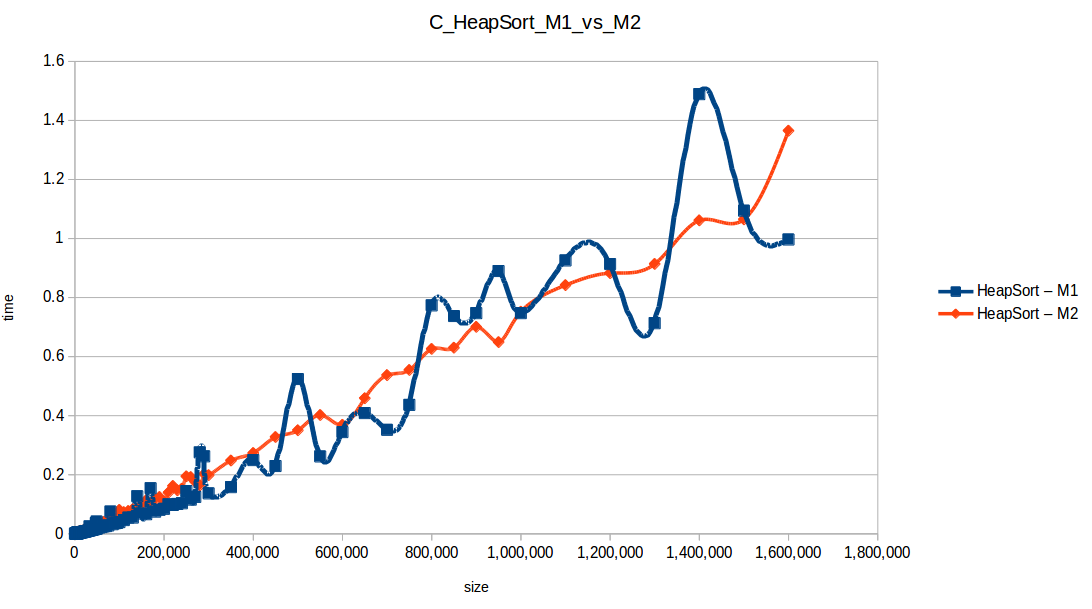
Montones (Heapsort): O(n log n)
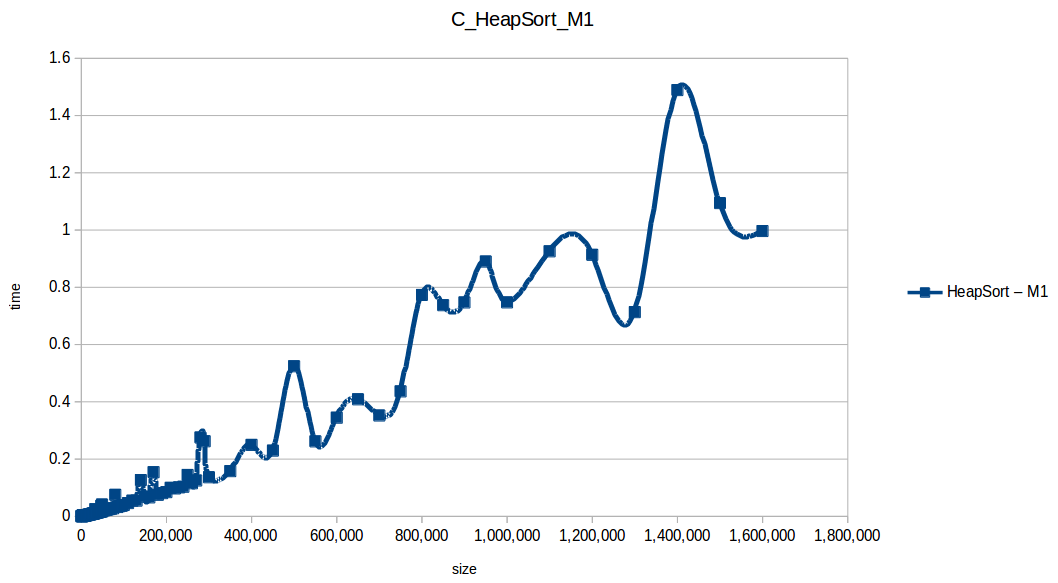
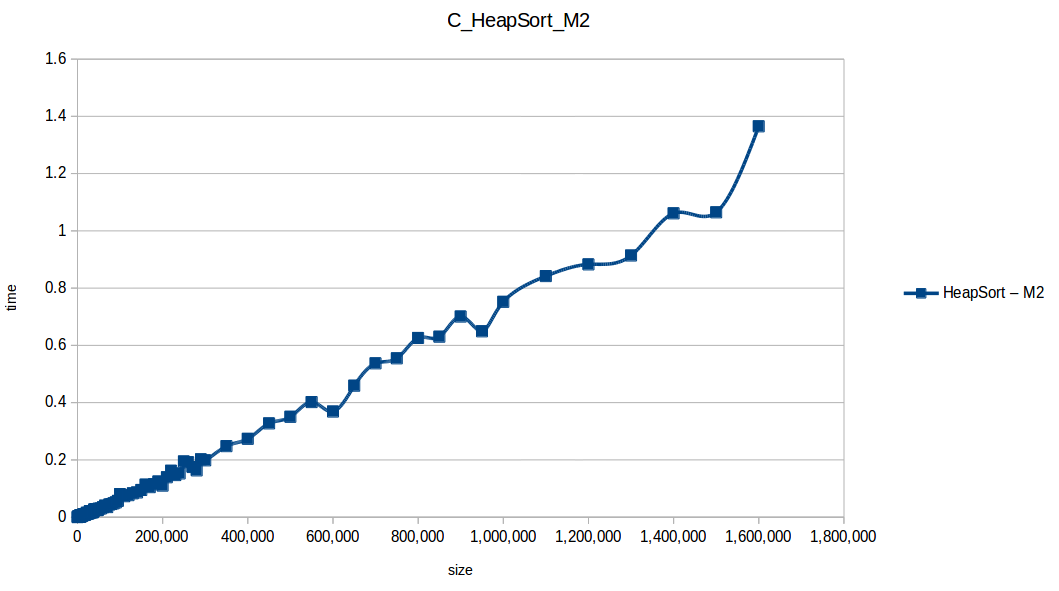
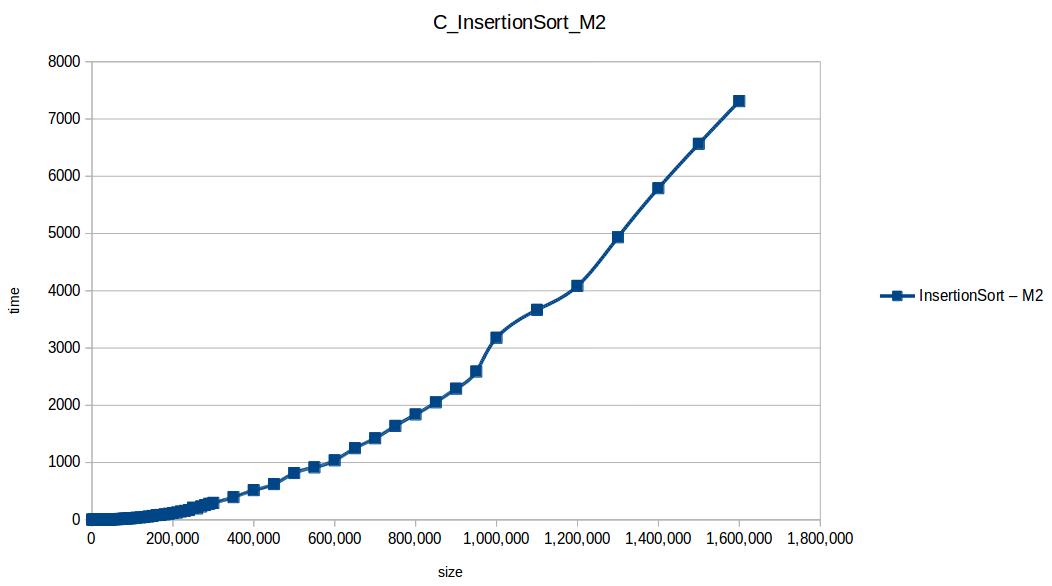
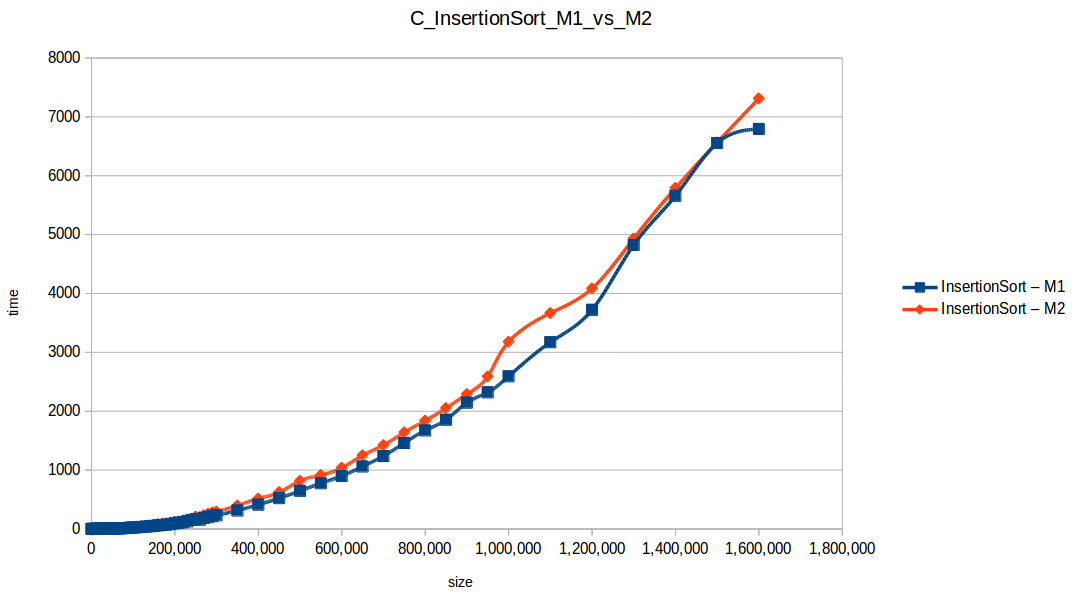
Inserción (Insertion Sort): O(n^2)

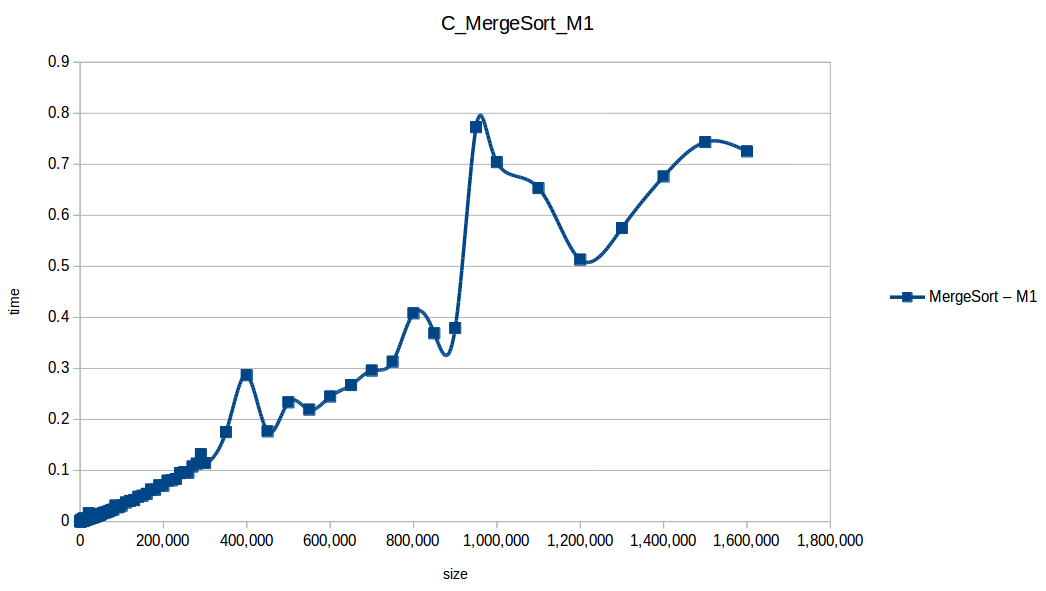
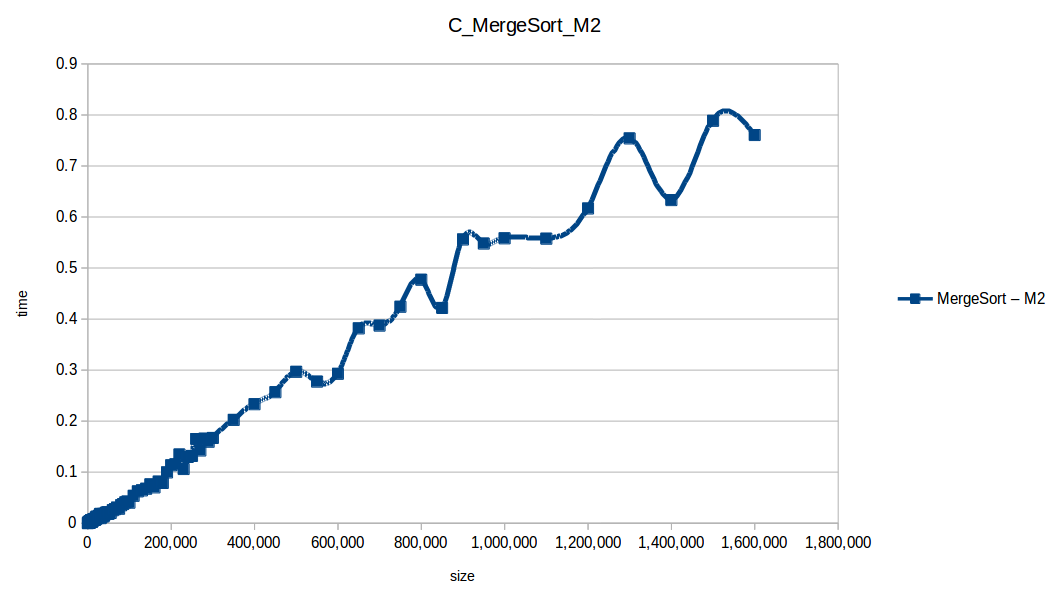
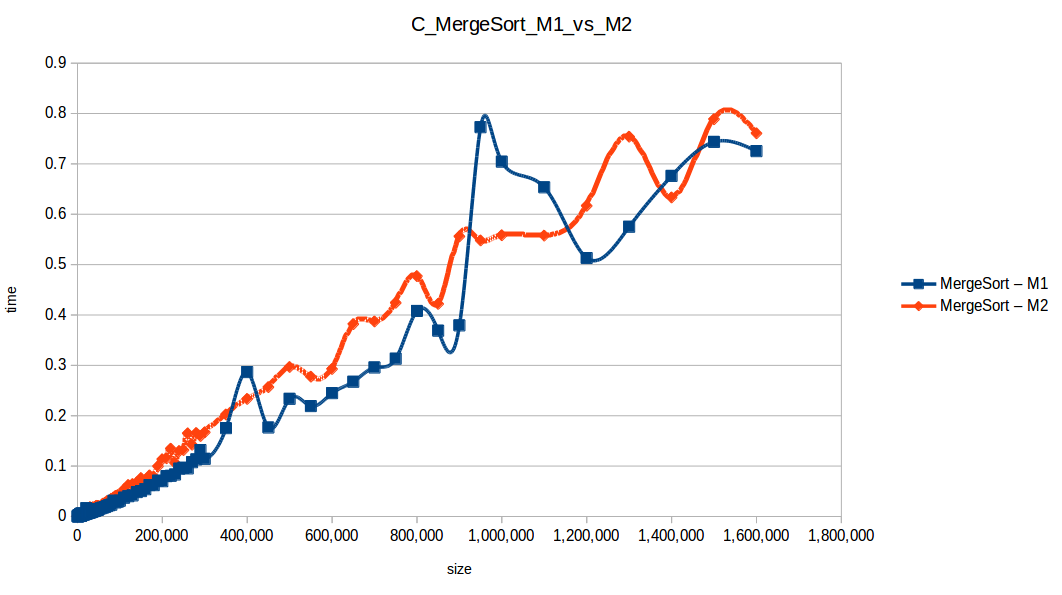
Mezclas (Merge Sort): O(n log n)
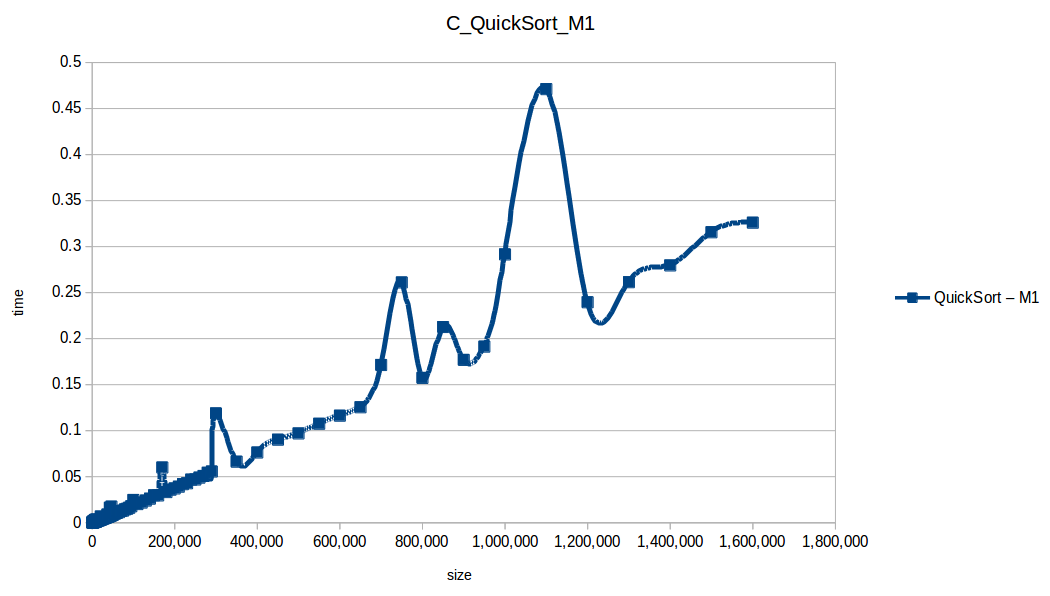
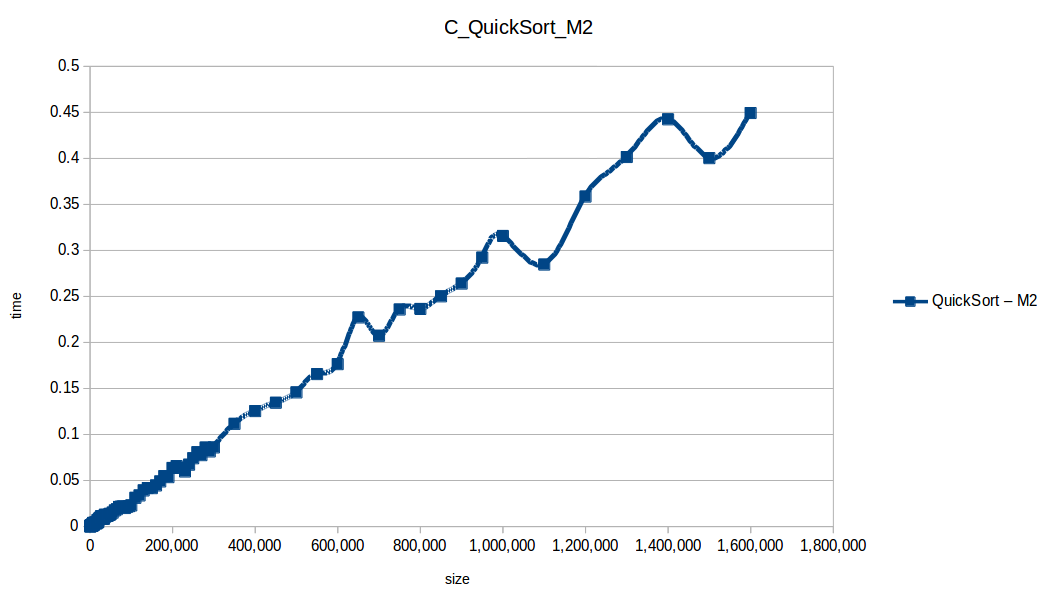
Rápido (Quicksort): O(n log n)
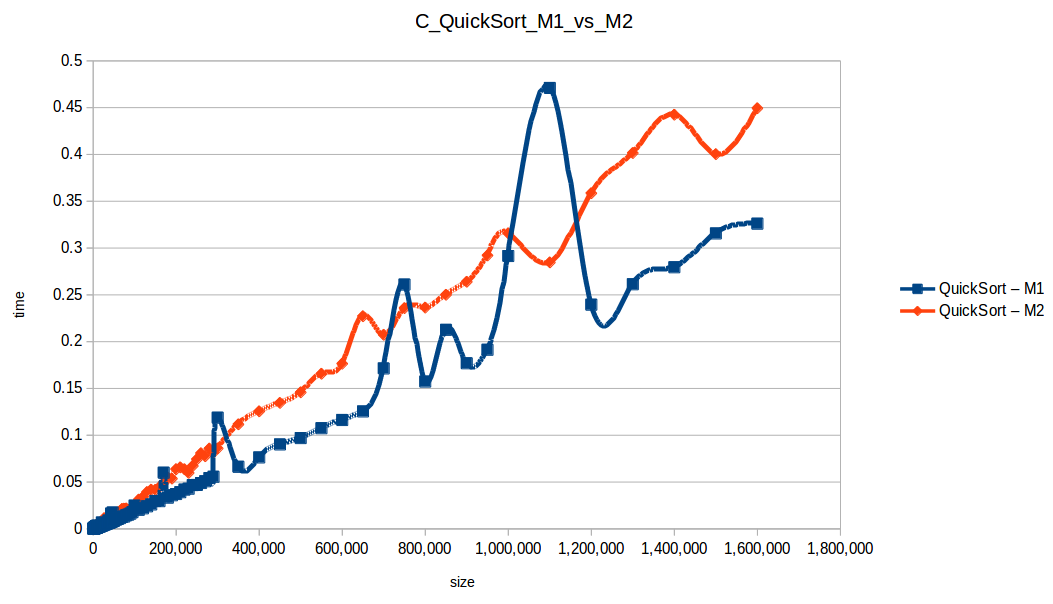
Selección (Selection Sort): O(n^2)
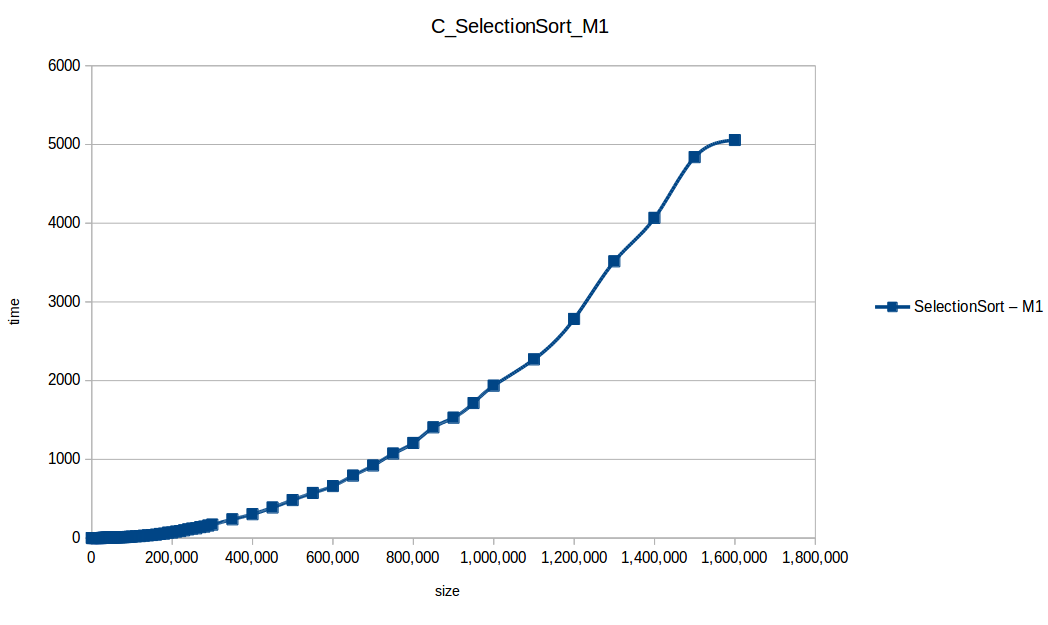
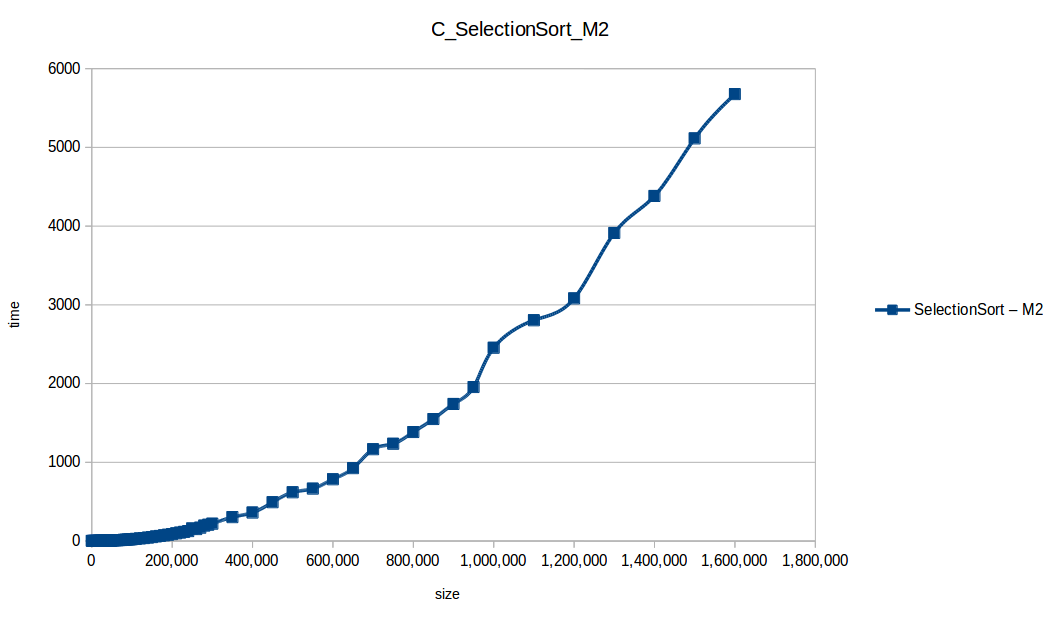
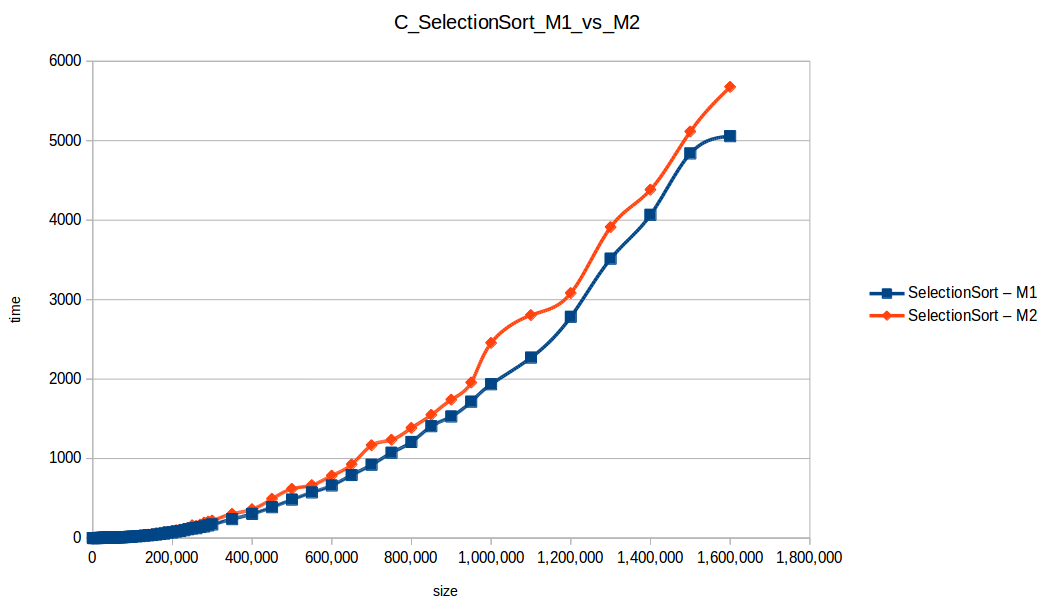
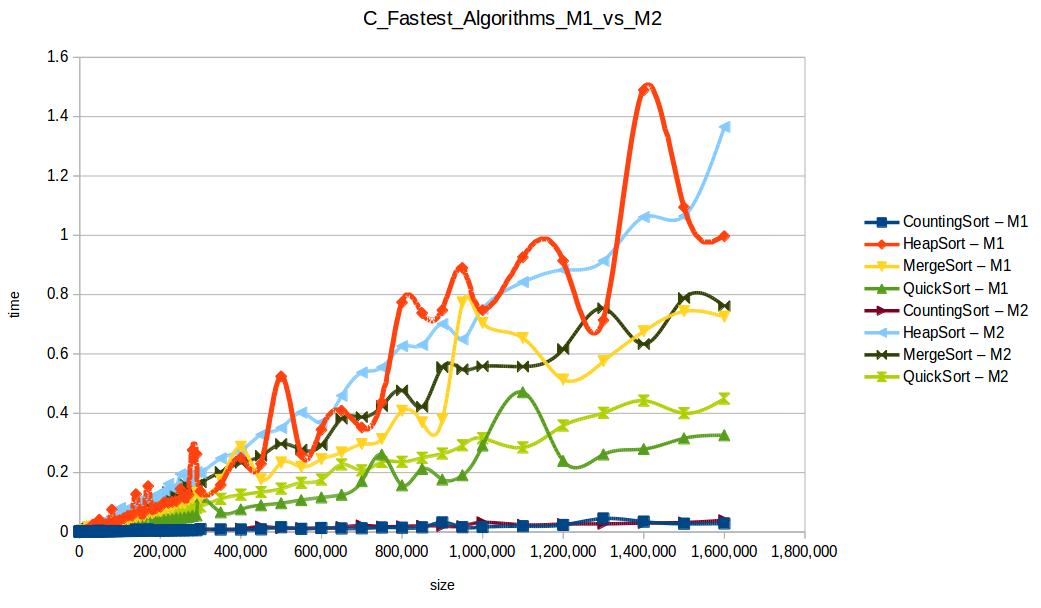
Como se puede observar en cada imagen se muestra la gráfica de cada algoritmo, primero en M1, luego en M2 y por último una tercera gráfica comparando ambas, donde la curva azul representa M1 y la linea naranja M2; como resultado de la simple observación, se puede concluir que M1 fue superior a M2, al menos por un pequeño margen en algunos casos. Pero ¿por qué es esto posible? acaso M2 no tenía el doble de recursos que M1? dejaré esta incognita para más adelante, primero determinemos cual de los algoritmos fue el ganador, cosa que de antemano deberíamos ya suponer con solo conocer cada una de las complejidades algoritmicas:
Gráfica comparativa de todos los algoritmos
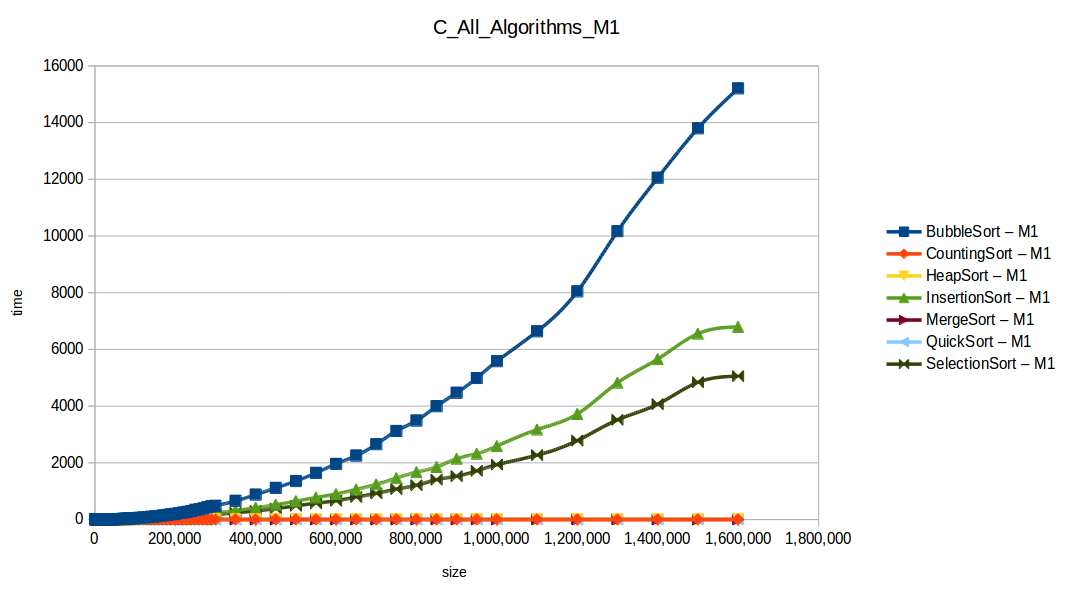
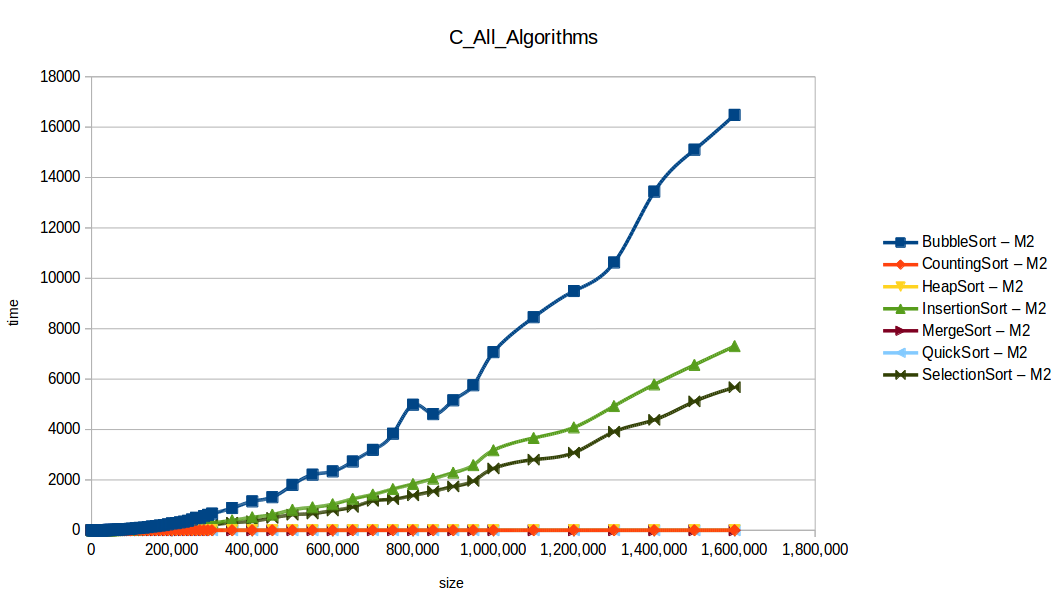
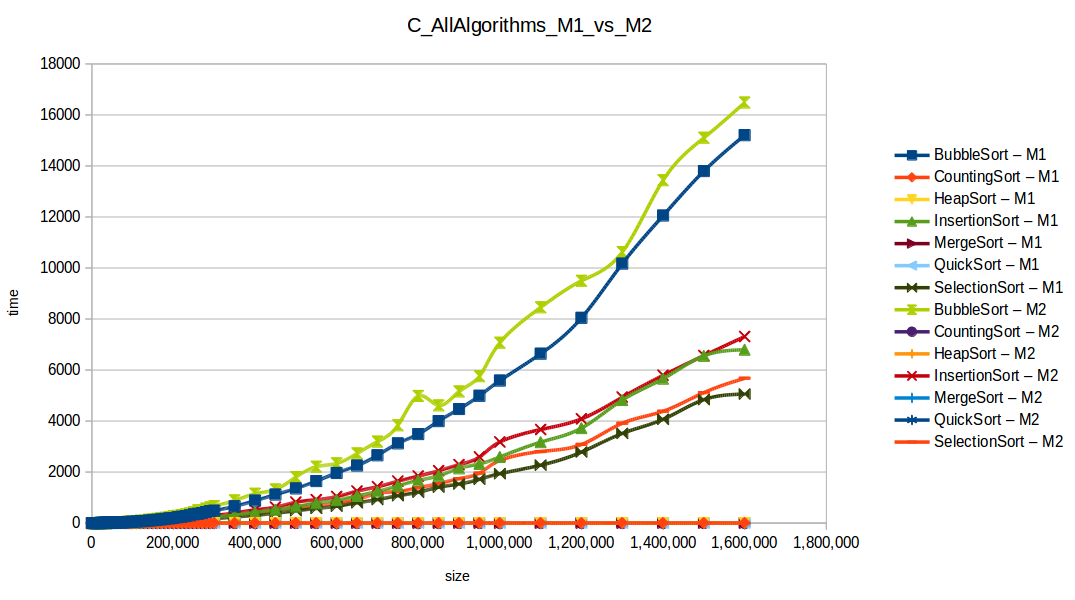
Como se puede observar en esta gráfica comparativa, no podemos conocer a ciencia cierta quien fue el ganador, dado que hay 4 algoritmos que se solapan entre si debido a la escala de la gráfica, y corresponden al quickSort, mergeSort, heapSort y countingSort, pero con total seguridad tenemos un claro perdedor, el cual fue el algoritmo burbuja con una complejidad algoritmica de O(n^2), seguido del insertionSort y el selectionSort, los cuales tienen igual una complejidad de O(n^2) pero sus implementaciones son un poco más eficientes dado que se hacen menos comparaciones, pero no dejan de ser algoritmos poco competentes.
Las consideraciones anteriores son un claro ejemplo de los retos que enfrentamos día a día quienes trabajamos en ciencias de la computación, existe una gran cantidad de lenguajes de programación, herramientas y soluciones diversas a un mismo problema, pero cada una con un campo de acción enfocadas a condiciones específicas.
A continuación imprimiré los últimos 7 tiempos obtenidos para cada algoritmo y para cada máquina en segundos, tener en cuenta que la primera columna size representa la cantidad de datos a ordenar.
Tiempos de respuesta en la máquina 1
Tiempos de respuesta en la máquina 2
Dando un vistazo a estas tablas ya deberíamos conocer el ganador, pero ya que una imagen vale más que mil palabras vamos a ello y ahora graficaremos solo los algoritmos veloces, que son el quickSort, mergeSort, heapSort y countingSort, de los cuales casi ninguno supero 1 segundo ordenando 1,600,000 de datos:
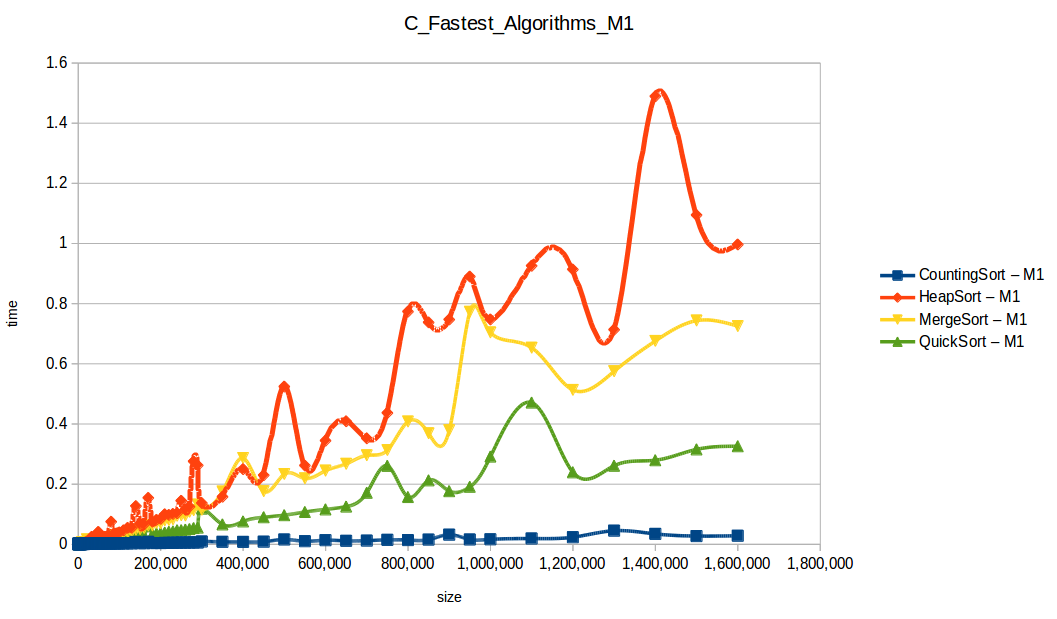
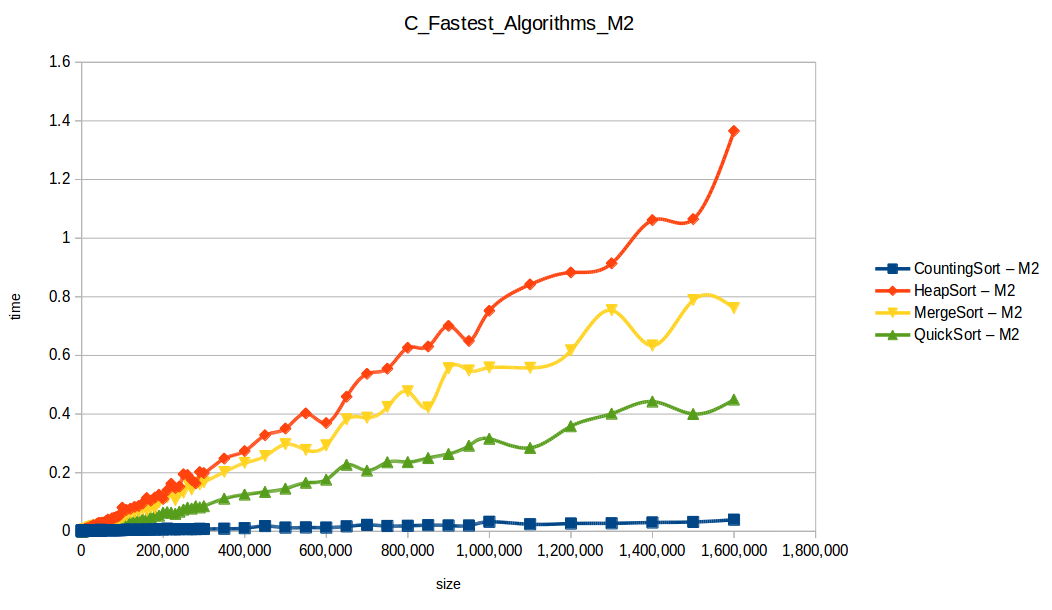
Como ya se debe suponer el claro ganador fue el algoritmo de contéo (countingSort) con una complejidad algoritmica de O(n+k), siendo n la cantidad de datos a ordenar y k el tamaño del vector auxiliar (máximo - mínimo). Pero no todo es color de rosas para el algoritmo de contéo, debido a que tiene una gran limitación, la cual es que solo funciona con numeros enteros, dado que requiere de un vector auxiliar donde almacenar la cuenta de cada valor; por otro lado incluso cuando queremos ordenar solo numeros enteros si la diferencia entre el máximo y el mínimo de los datos a ordenar es muy grande, el vector auxiliar requerido implica un consumo excesivo de memoria, lo cual hace que la balanza se incline cada vez más en contra, pero como hemos probado, bajo condiciones específicas, el algoritmo de contéo es una de las mejores técnicas para ordenar datos, seguido del quickSort quien obtuvo el segundo lugar en este experimento, algoritmo con una complejidad de O(n log n), siendo uno de los más usados con el cual puedes ordenar también numeros reales; pero que igual que el algoritmo de contéo tiene sus falencias, dado que es un algoritmo probabilístico y hay casos extremos en los cuales la complejidad se puede elevar a O(n^2), dependiendo de la distribución de los datos y una mala elección de pivote.
Máquina 1 vs Máquina 2
Antes de terminar con este breve análisis, habíamos dejado una incognita unos parrafos atrás, donde encontramos que la máquina 1 venció a la máquina 2 en tiempos de respuesta, pero ¿como fue posible si poseía el doble de recursos? La respuesta la encontramos en la capacidad de procesamiento de cada máquina, en teoria en M2 tenemos a disposición dos nucleos de procesamiento para ejecutar instrucciones, ¿pero realmente ambos nucleos estan corriendo en paralelo para dar solución a los procesos de ordenamiento? la respuesta en este caso es NO, nuestros algoritmos no estan programados de forma tal que puedan usar todos los nucleos de la máquina, para ello deberíamos usar hilos y poder dividir tareas de forma tal que nuestros procesos puedan hacer varias cosas al tiempo por medio del uso de hilos, pero a pesar de lo anterior, dentro los algoritmos que estamos analizando no todos se pueden paralelizar, dado que siguen una rigurosa secuencia de tareas.
Hasta este punto lo único que hemos aclarado es que en cuanto a capacidad de procesamiento, ambas máquinas se encuentran en las mismas condiciones (1 nucleo de procesamiento en uso), pero en este caso M2, deberia seguir teniendo la ventaja, dado que posee el doble de memoria RAM, pero esto no siempre es un factor determinante para que un algortimo sea más eficiente.
En este caso existe una mejor explicación asociada a las capacidades del procesador; cada nucleo de procesamiento tiene asociada una frecuencia de reloj que permite definir la velocidad a la cual se pueden ejecutar tareas por segundo, la cual está expresada en Hertz, es decir, mide la cantidad de ciclos de procesamiento en un segundo de tiempo (Cantidad de ciclos que suceden en un segundo).
Esta medida se presenta en las siguientes unidades:
- 1 Hertz (Hz)= un ciclo/segundo
- 1 Kilohertz (KHz)= 1024 Hz
- 1 MegaHertz (MHz)= 1024 KHz
- 1 GigaHertz(GHz)= 1024 MHz
- 1 TeraHertz (THz)= 1024 GHz
Por lo tanto si un procesador tiene una velocidad de 1 MHz, esto se traduce en que el procesador ejecuta 1 millon de ciclos en un segundo. Así que saquemonos de dudas y veamos cual es la frecuencia de procesamiento de cada una de nuestras máquinas:
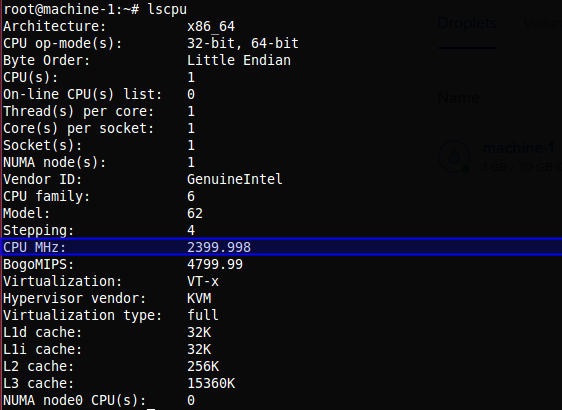
# Accedemos al servidor y ejecutamos el comando lscpu, el cual entrega información acerca de la arquitectura de los CPU presentes en el sistema.
$ lscpu
Información del sistema para la M1
Información del sistema para la M2
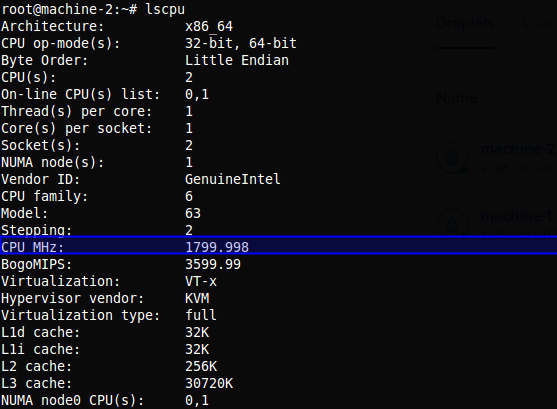
Rápidamente obtenemos la respuesta a nuestra pregunta; M1 tiene una frecuencia de procesamiento de 2399.998 MHz, mientras que M2 tiene 1799.998 MHz por cada nucleo, osea que mientras M1 puede procesar casi 2400 millones de instrucciones por segundo, M2 solo puede procesar en el único nucleo que tiene en uso casi 1800 millones de instrucciones por segundo, lo cual es un factor muy relevante para nuestro experimento.
¿Pero entonces acaso la memoria RAM extra que poseemos en M2 no influye en nada?
La respuesta es que si influye, pero en nuestro experimento no mucho, o tal vez en simplente no, dado que nuestras máquinas se crearon desde cero y no se estan utilizando para nada correr otros procesos, por lo cual tenemos a disposición todos los recursos de la máquina sobre nuestros algoritmos de ordenamiento.
¿Como podríamos aprovechar esos recursos extra en nuestro experimento?
Si nos vamos un poco atrás, recordamos que el experimento lo pausamos al llegar a una cantidad de 1,600.000 datos, ya que los algoritmos de complejidad O(n^2) se estaban demorando varias horas para correr cada prueba, ¿que tal si corremos solo los algoritmos eficientes (los cuales apenas y llegaron al umbral de 1 segundo) y comprobamos hasta donde son capáz de aguantar nuestras máquinas?
Manos a la obra (los resultados se pueden encontrar en results/analysis.ods:
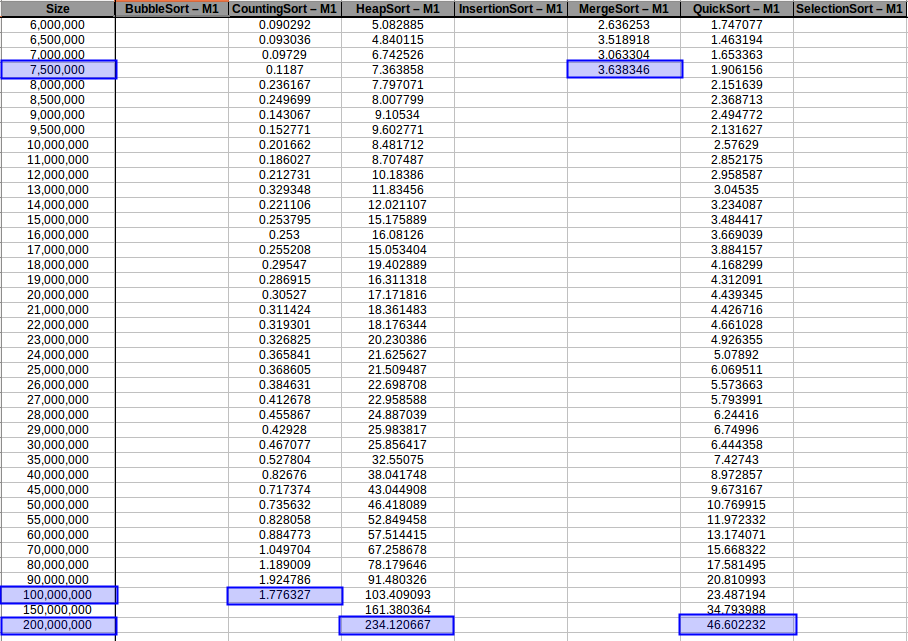
Capacidad máxima de procesamiento para M1 con 1GB de RAM
Capacidad máxima de procesamiento para M2 con 2GB de RAM
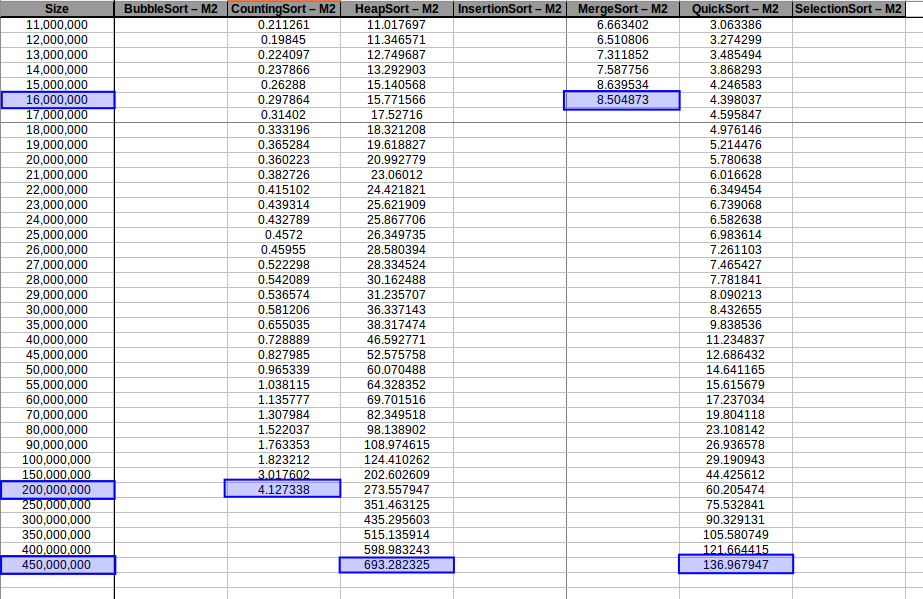
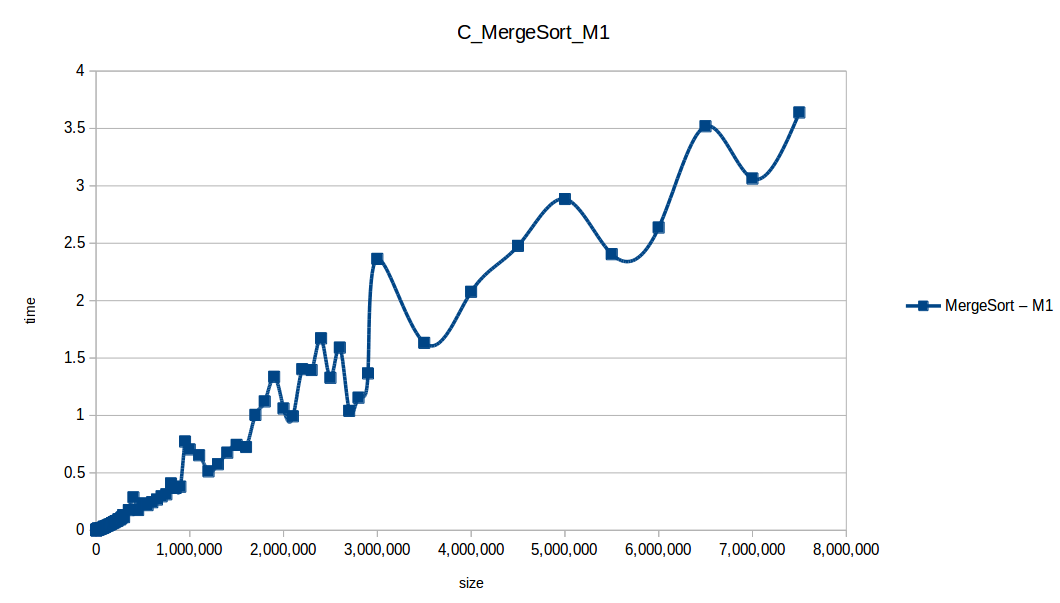
En los resultados obtenidos, se puede ver claramente como la capacidad de memoria extra le permitio a M2, procesar el doble o en algunos casos el triple o más de lo que pudo M1, todo esto depende de como cada algoritmo esta diseñado, por ejemplo vemos que el mergeSort fue el que menos aguanto, debido a que utiliza un arreglo auxiliar de tamaño igual a N, por lo tanto ocupa dos veces más memoria de la que ocuparía por ejemplo el quickSort que no requiere arreglo auxiliar.
A continuación se muestra de nuevo una gráficas de tiempos de respuesta para los algoritmos más veloces:
Conteo (Counting Sort) hasta el máximo volumen de datos: O(n+k)
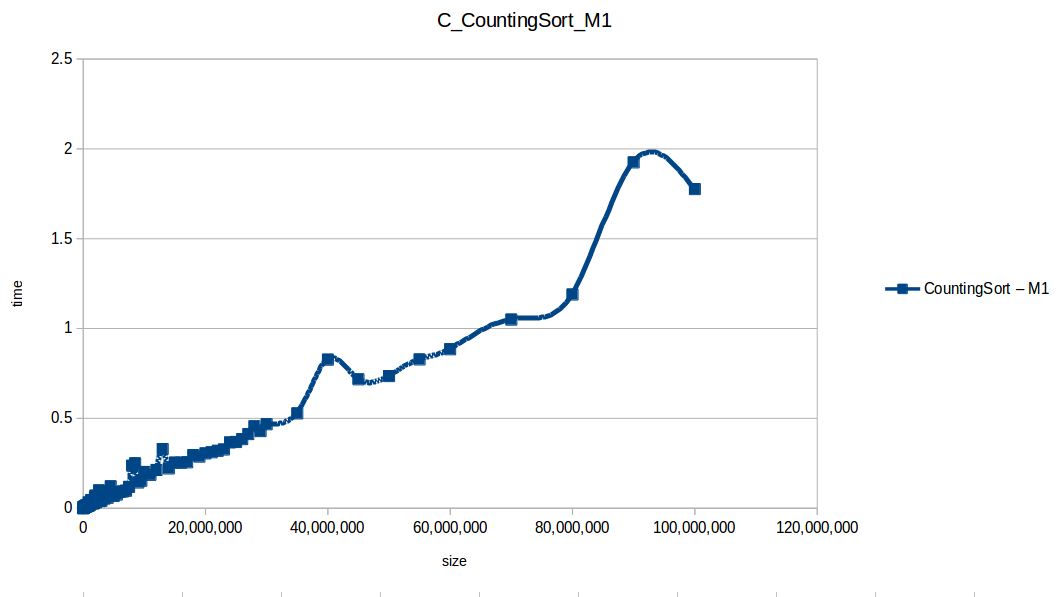
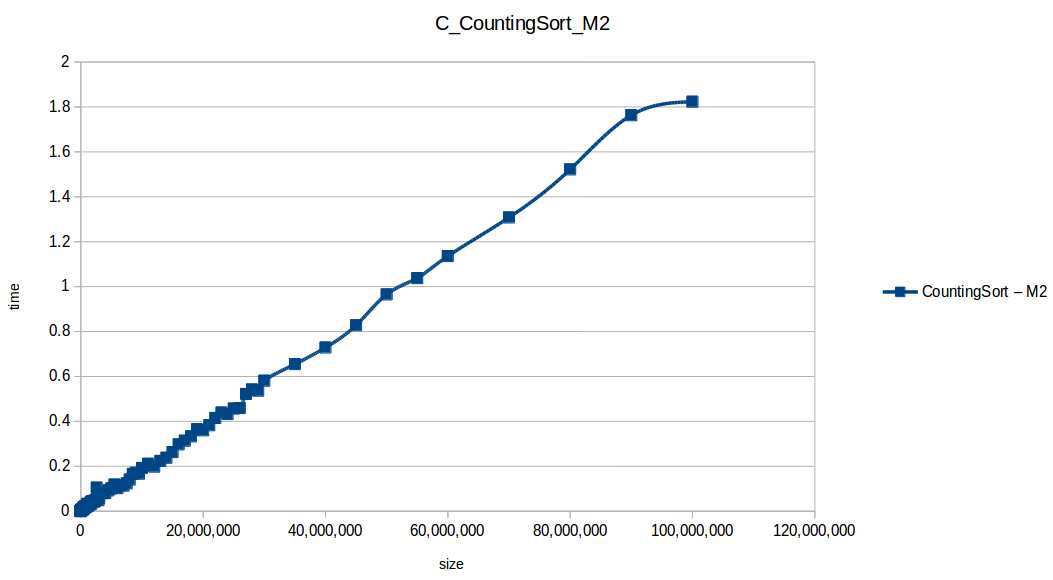
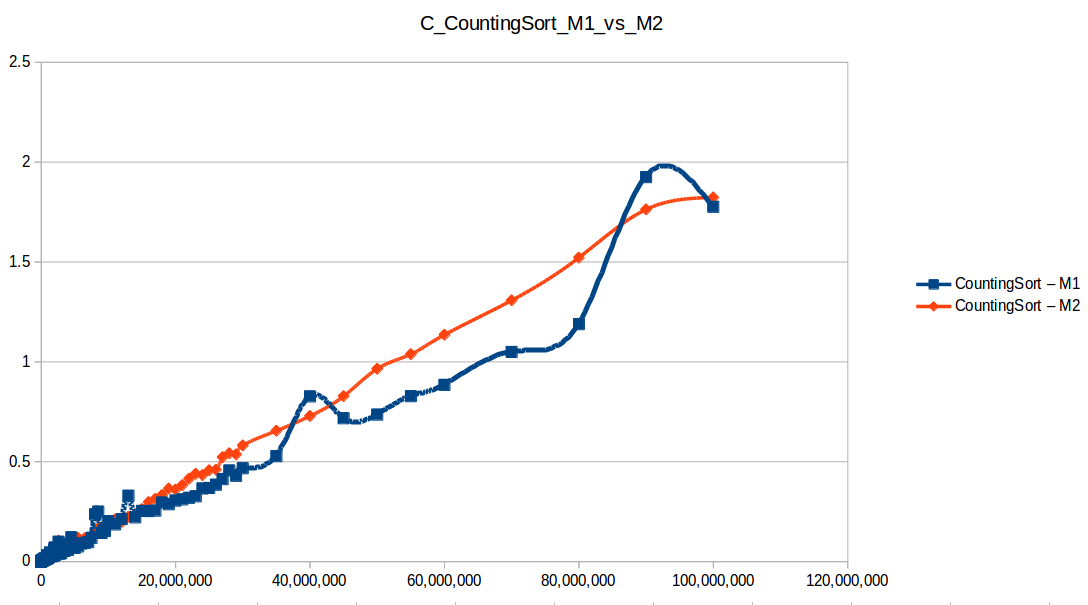
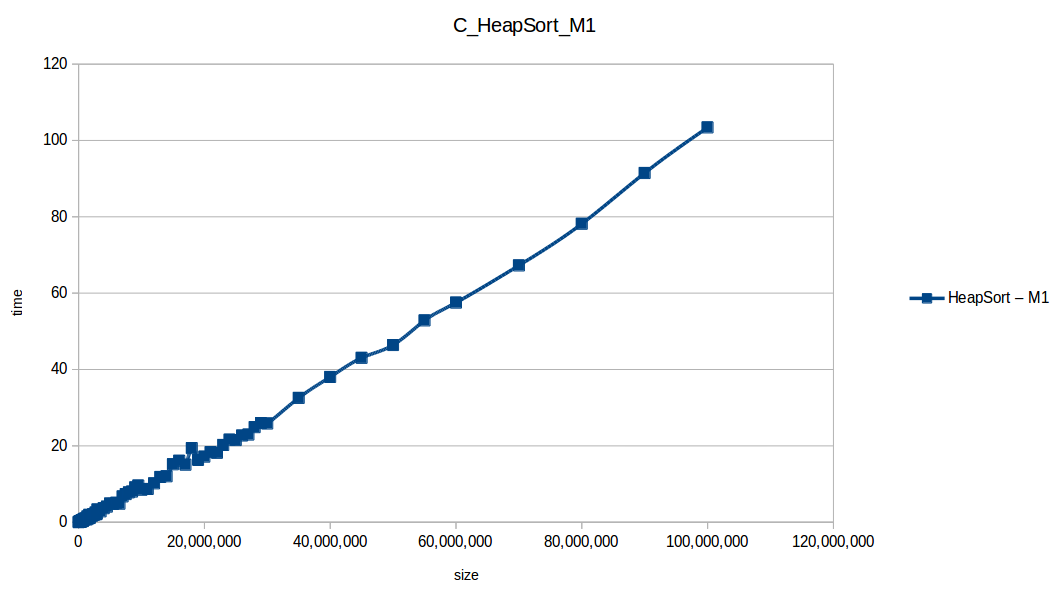
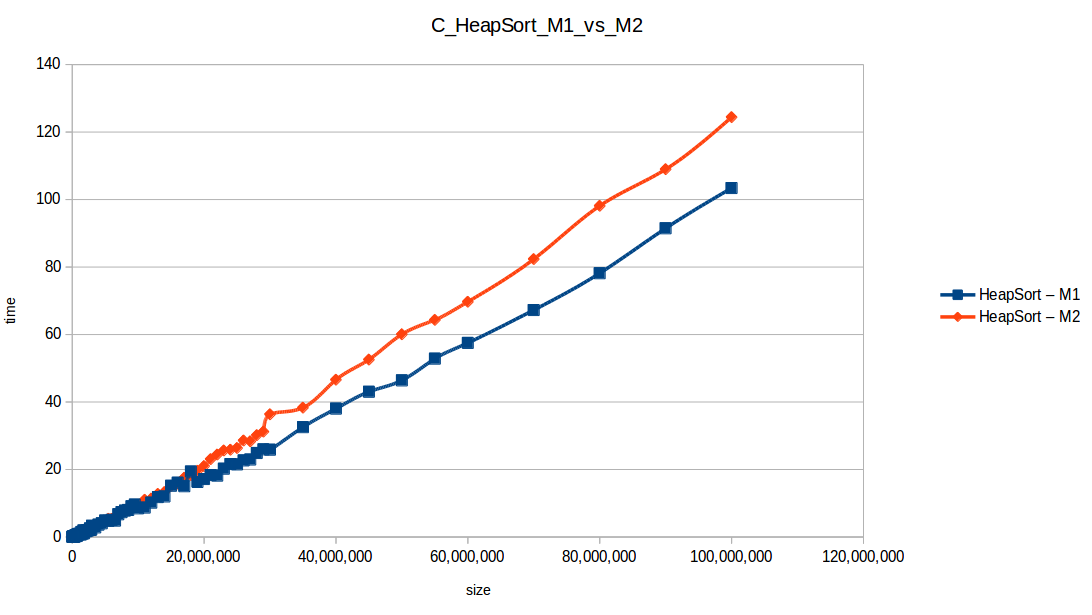
Montones (Heapsort) hasta el máximo volumen de datos: O(n log n)

Mezclas (Merge Sort) hasta el máximo volumen de datos: O(n log n)
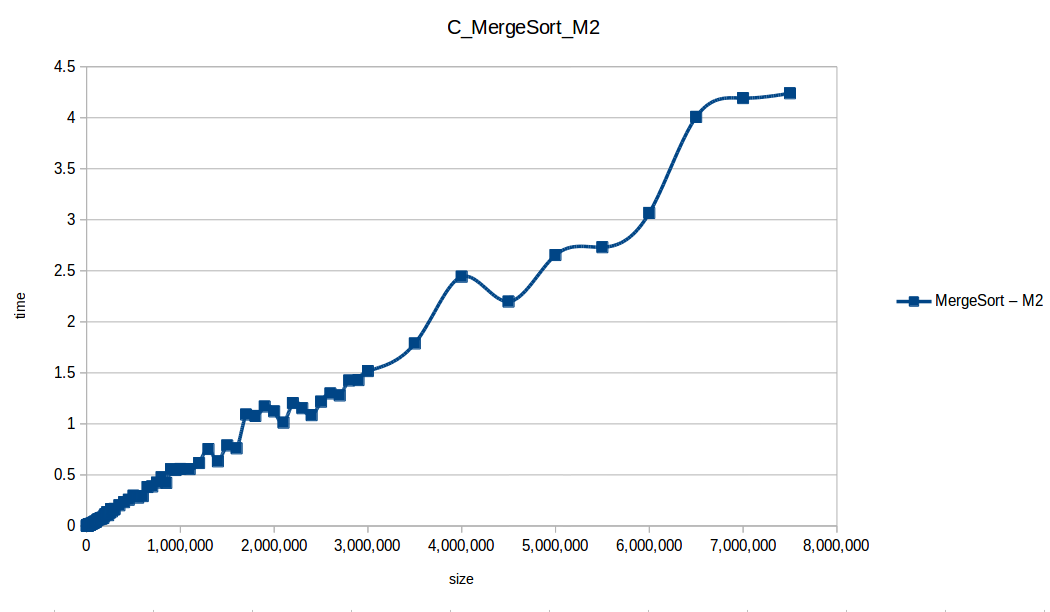
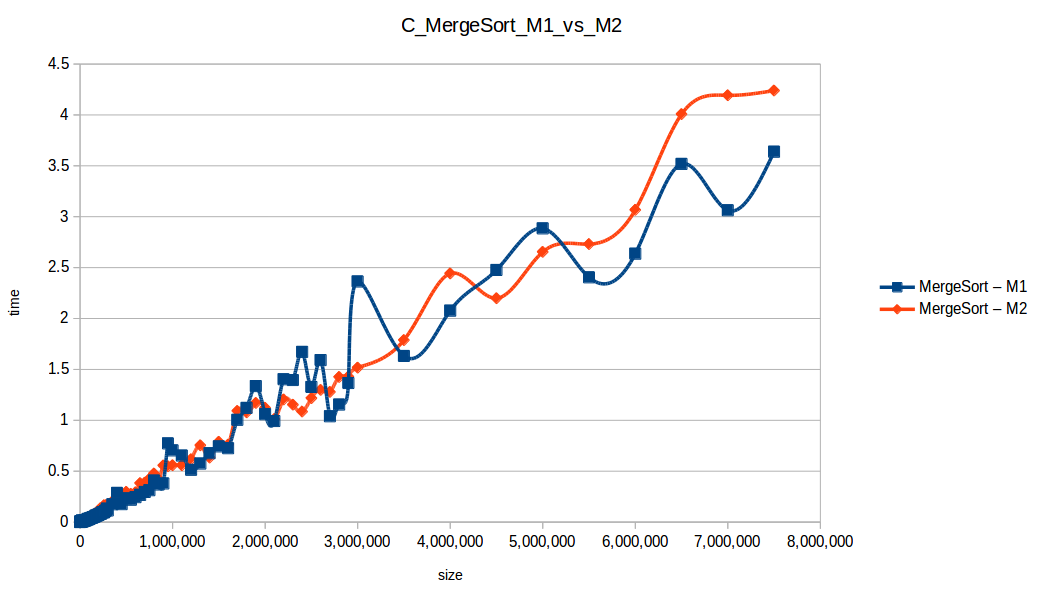
Rápido (Quicksort) hasta el máximo volumen de datos: O(n log n)
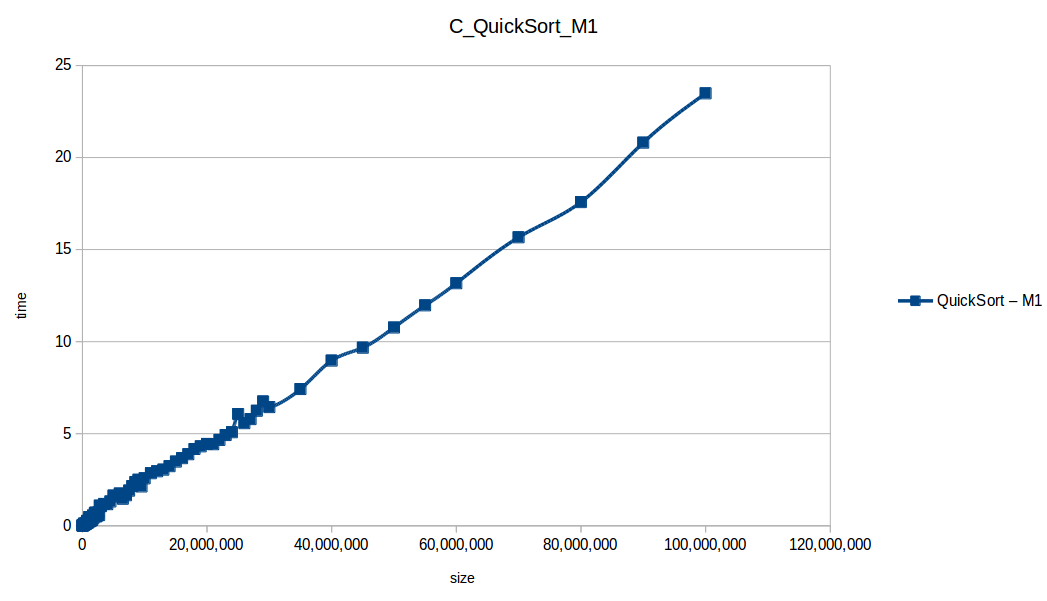
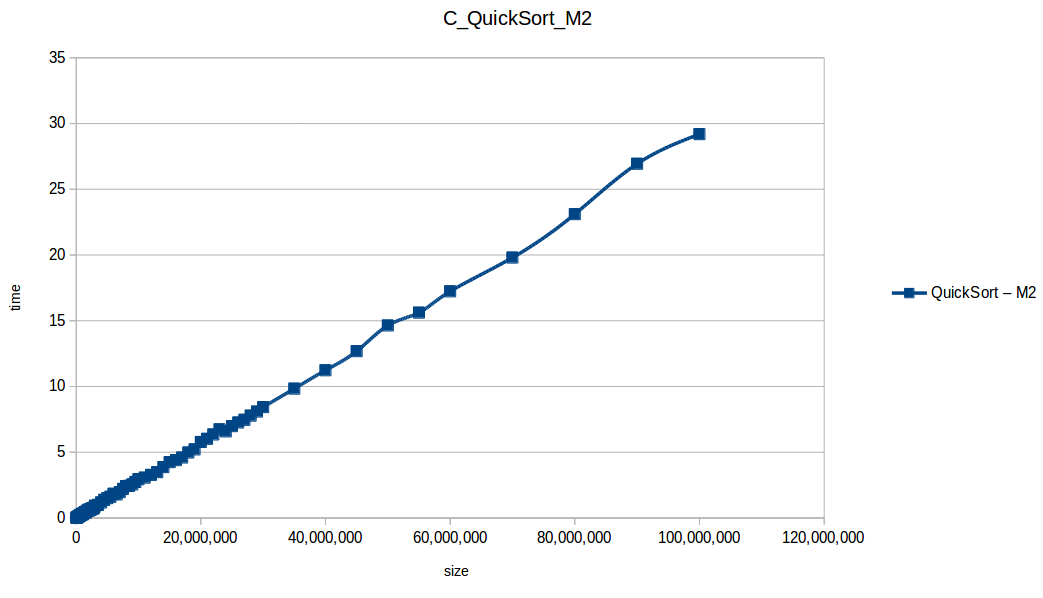
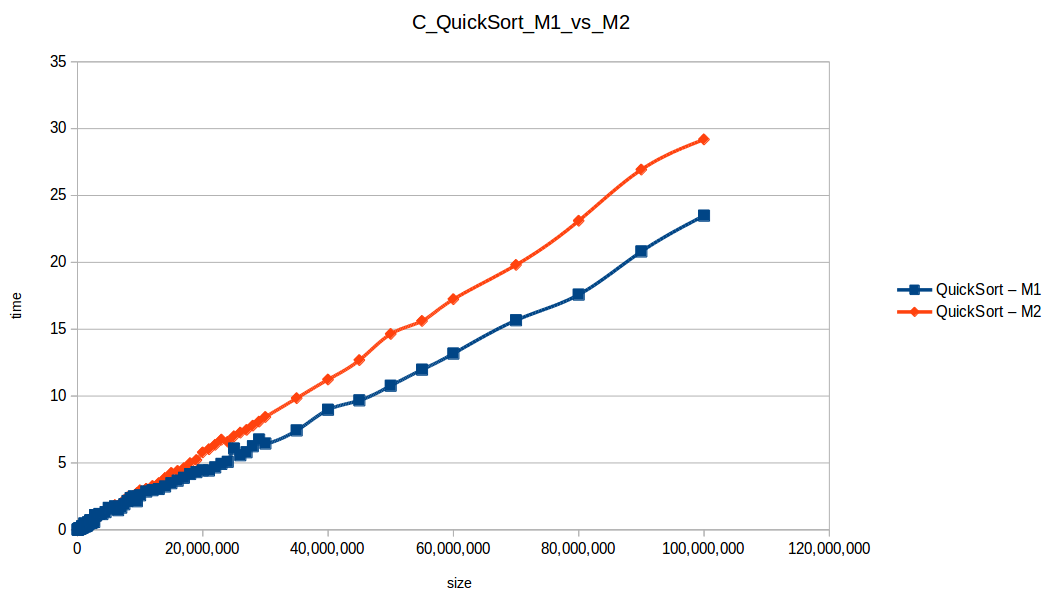
Gráfica comparativa de los algoritmos eficientes hasta el máximo volumen de datos
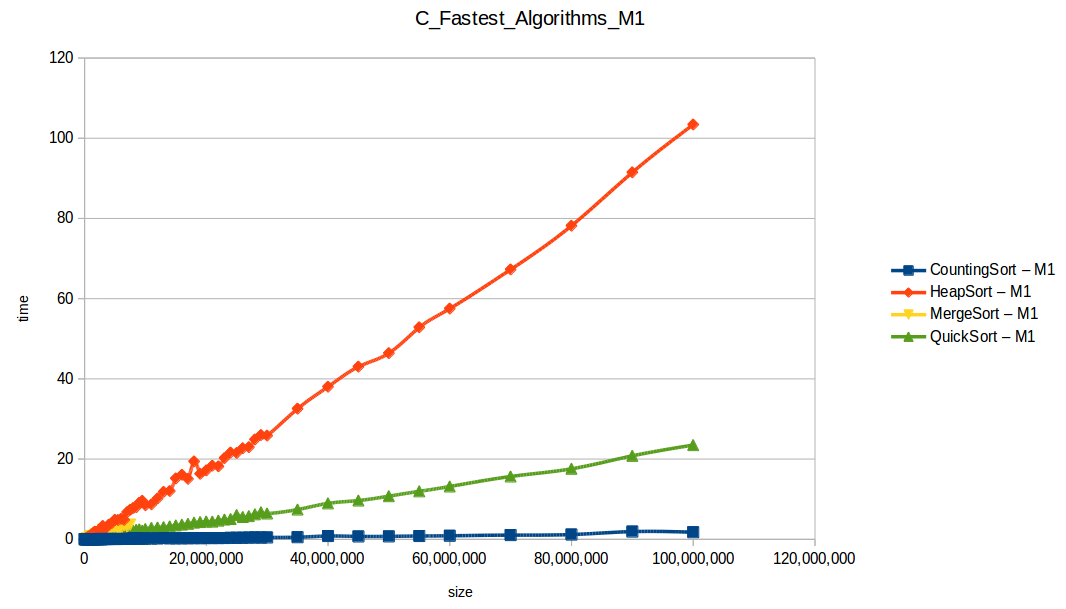
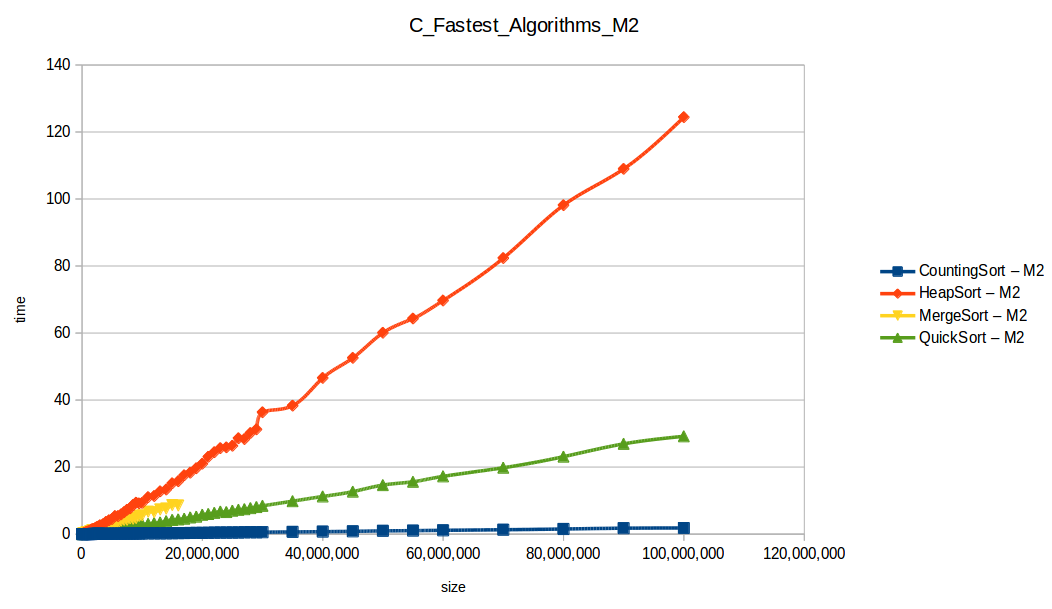
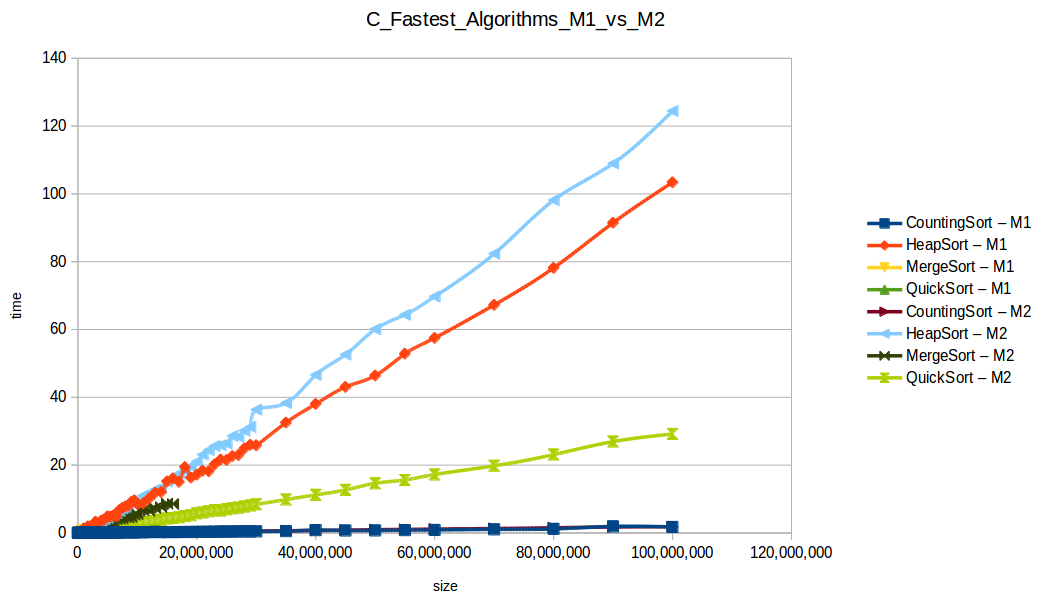
Tras analizar las nuevas gráficas obtenidas nos damos cuenta que al extender un poco el experimento, un mayor volumen de datos nos ha permitido obtener curvas con un comportamiento más constantes, menos caóticas y uniformes, que podemos comparar con las funciones de complejidad de cada algoritmo, además de poder conocer como los diferentes recursos de un sistema pueden influir en el procesamiento y obtención de resultados.
Por último espero que todo este análisis le resulte útil algún día a quienes se inician en ciencias de la computación, o quienes quieran repasar conceptos. ¡Happy coding!
Recursos: Repositorío con código en github
—
“La inteligencia consiste no sólo en el conocimiento, sino también en la destreza de aplicar los conocimientos en la práctica” — Aristóteles



